Incremental Refresh (IR) optimizes performance and reduces data processing time by refreshing only new or changed data instead of reloading everything. However, after configuring IR, it’s essential to verify that it works correctly. There are cases where everything seems fine initially—only to later discover that data isn’t being partitioned as expected. This guide explains how to confirm that your IR configuration is functioning properly and how to troubleshoot potential issues.
For an introduction to incremental refresh in Power BI, please consult the official documentation here and here. In particular, review the key concept of query folding in case you are not familiar with it.
Key Checks for Incremental Refresh
Two primary checks are essential to verify the effectiveness of IR:
- Ensuring partitions are created correctly
- Examining row counts within each partition
The methods for verifying these differ for semantic models and dataflows.
Checking Incremental Refresh in Semantic Models
For semantic models, the following tools help inspect partitions:
- Tabular Editor – View partitions and their properties.
- DAX Studio – Query partitions via dynamic management views (DMVs).
- SQL Server Management Studio (SSMS) – View partitions and row counts.
Note: These tools require that the models reside in Premium capacities.
To connect with any of these tools, we need to use the connection link to the corresponding workspace, available in Workspace settings. For example:
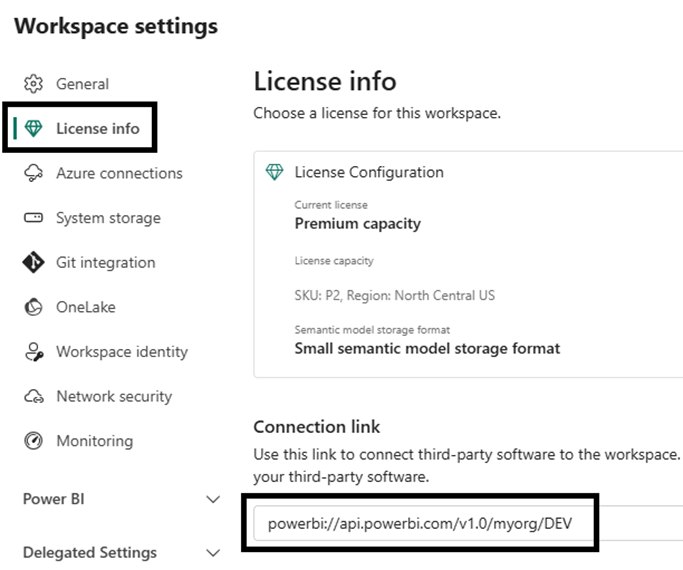
Tabular Editor
In Tabular Editor, connect like this, using the example link above:
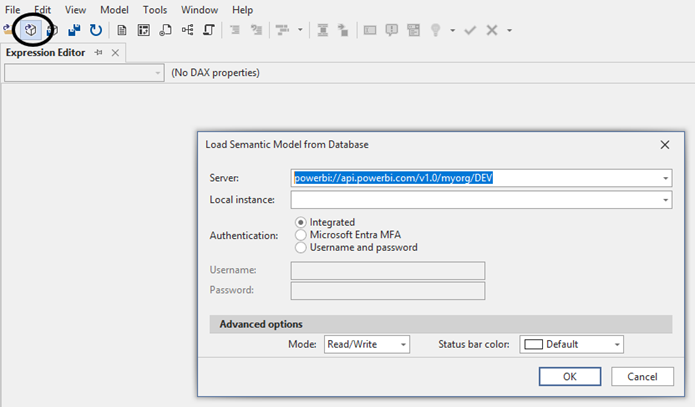
When we press Connect, we will be shown a list of the semantic models in the workspace. Once we choose a model, we can examine the partitions created and some properties about them, such as the granularity and the specific time period each covers. Just expand the Partitions folder for a table.
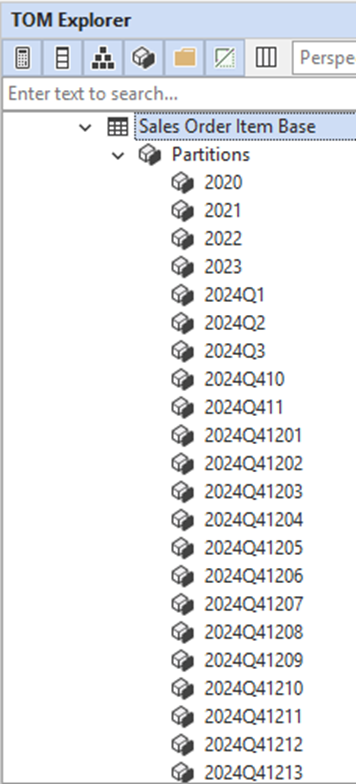

Recall from the official documentation that additional partitions will be created close to the “refresh partitions” period, for optimization purposes.
DAX Studio
In DAX Studio, we similarly connect and then choose a model.
In DAX Studio, we similarly connect and then choose a model.
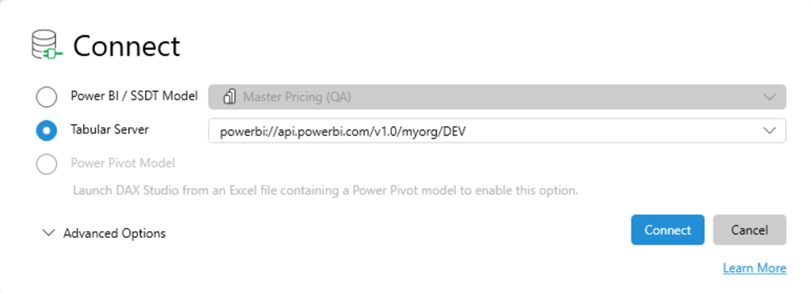
However, we need to use dynamic management views (DMVs) to examine partition information. First, we need the ID of the table we are interested in:
select *
from $SYSTEM.TMSCHEMA_TABLES
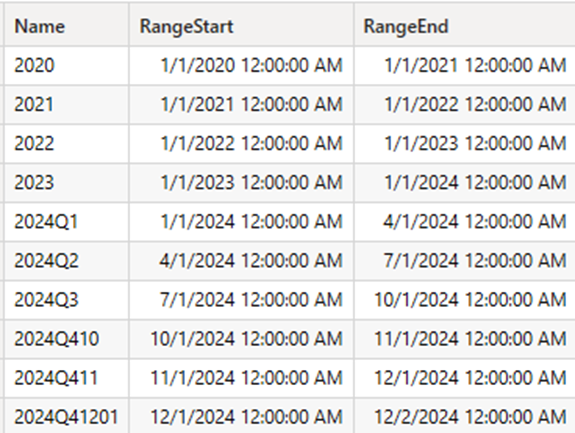
With that in hand, we query the schema partitions view:
select [Name], RangeStart, RangeEnd
from $SYSTEM.TMSCHEMA_PARTITIONS
where TableID = 14
This is a partial list of the results:
SQL Server Management Studio
To connect to a semantic model via SSMS, we choose an Analysis Services connection and authentication type:
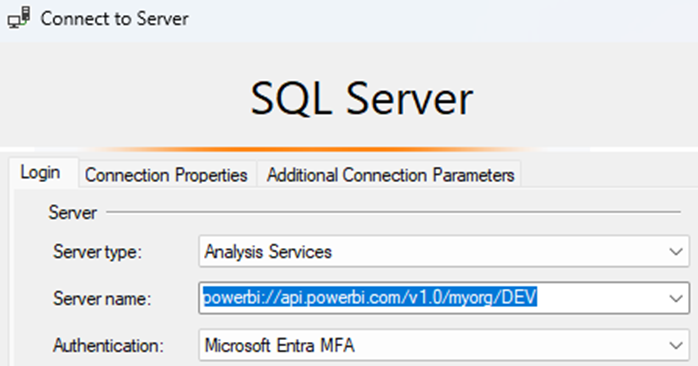
The semantic models available will be listed as databases once we connect. Then we navigate to the table we want to examine:
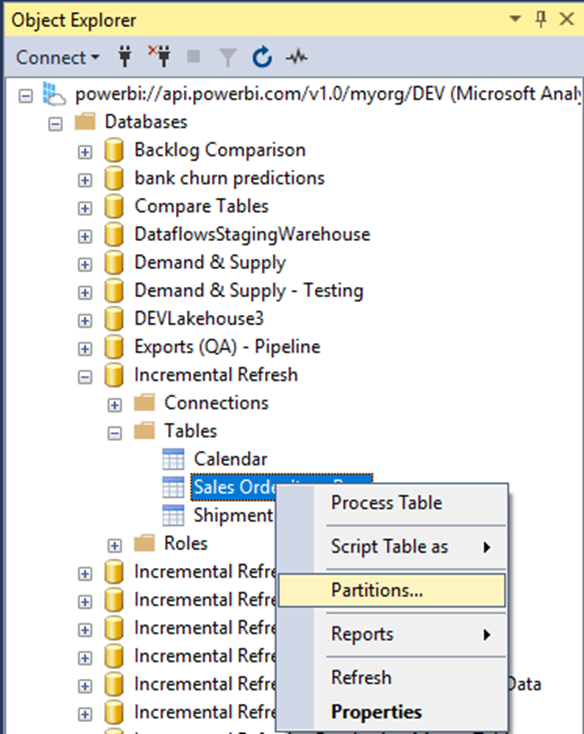
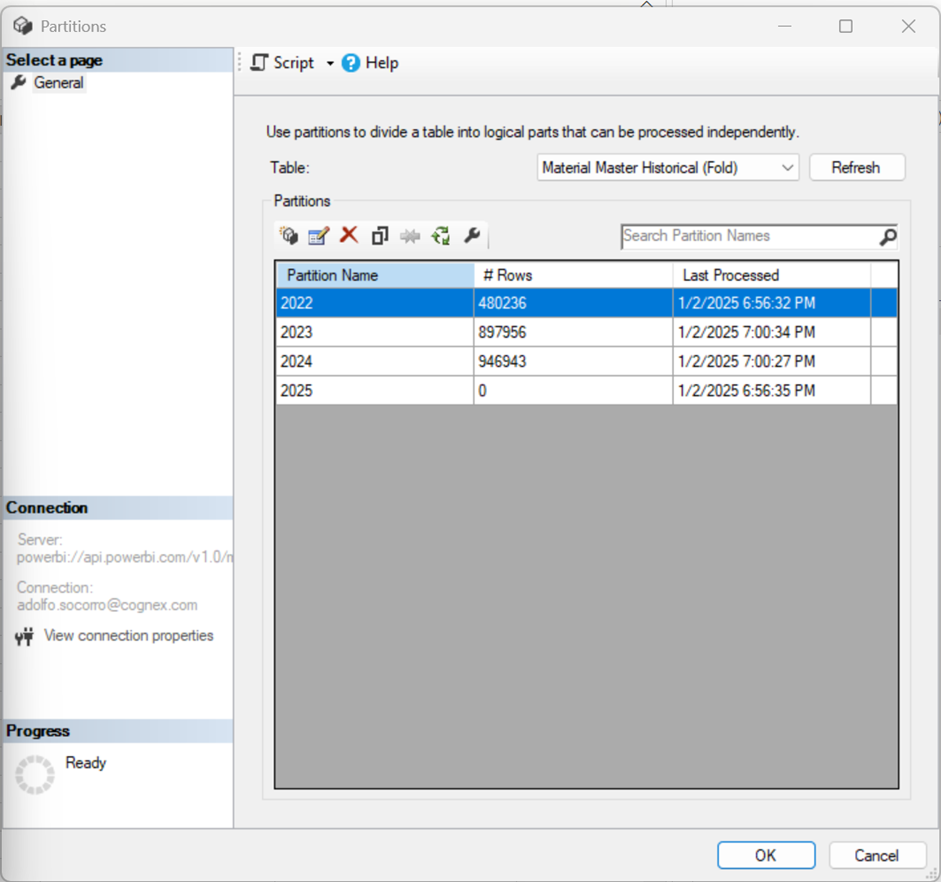
In the resulting window, we can examine partitions and row counts:
Checking Incremental Refresh in Dataflows
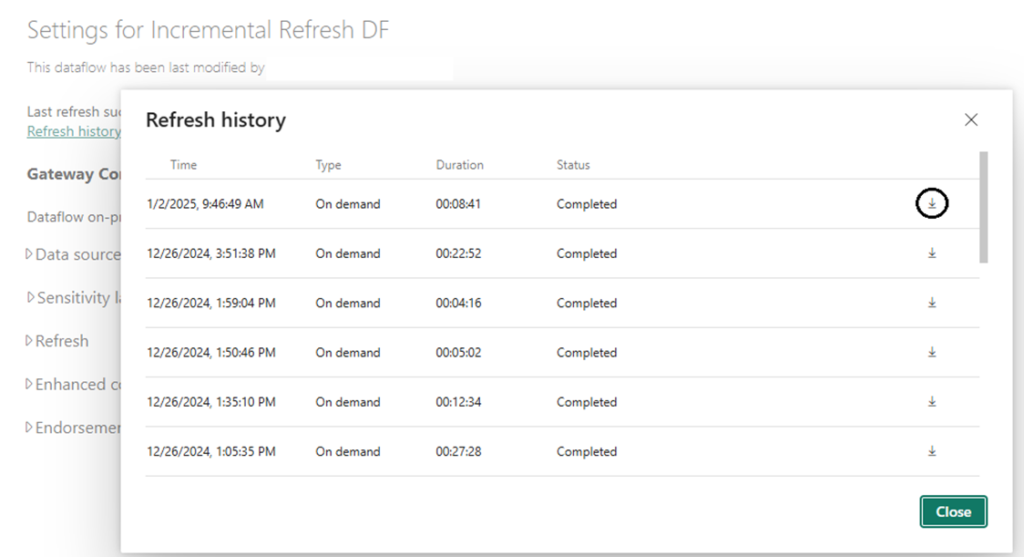
Dataflows do not have dedicated tools for partition inspection. Instead, use the Refresh History Log available in the Service:
For example, the screenshot below is the initial refresh log for two dataflow tables, one with IR and the other without it.
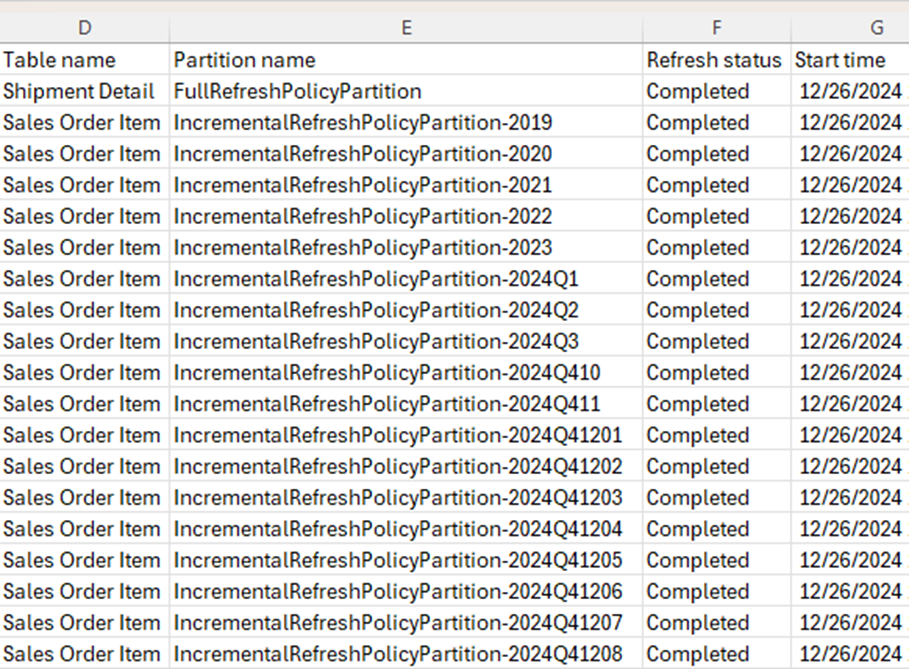
Notice the differences in the values in the Partition name column.
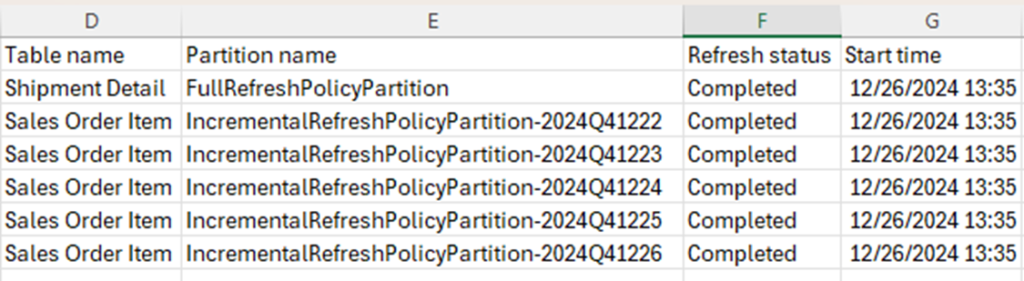
Subsequent refreshes only affect the refreshed partitions in the IR table. This is the full log, showing that the historical partitions were not refreshed:
Note: Incremental refresh for dataflows is only available in Power BI Premium capacities.
About Row Counts
The final check for ensuring that IR is configured properly is to validate the number of rows in each partition against the result of manual queries against the data source. We might discover slight variations at the edges of partitions that we might want to adjust by editing the query step in which we apply the RangeStart and RangeEnd parameters.
When it Goes Wrong: An Example
Of course, if with any of the methods above we don’t see partitions, something is off, and we need to review our configuration settings. However, observing partitions is not enough. The row counts need to make sense, at least at a high level.
In this query, our data source is a dataflow. The query does not fold, and we get a warning about it when setting up IR.
If we ignore the warning and then examine the results, we see this:

Clearly, something is wrong with all the counts being the same.
Why would one be tempted to ignore the warning, though? Well, it happens that for some other data sources, such as SAP HANA, that same query produces good partitions. Also, sometimes the Power Query engine will, at run time, reorder query steps to maximize the number of steps that fold. So, if based on that knowledge you were to ignore the warning thinking everything would or could turn out right, your best move is to check the resulting partitions.
Common Issues and Troubleshooting
If partitions are missing or row counts seem incorrect, consider the following:
1. Partitions Not Appearing
- Possible Causes:
- IR not enabled properly.
- Query folding issues prevent partitioning.
- Refresh policy misconfigured (e.g., incorrect date range).
- Solutions:
- Double-check IR settings in Power BI Desktop.
- Ensure the RangeStart and RangeEnd parameters are set correctly.
- Verify that query folding is occurring.
2. Incorrect Row Counts
- Possible Causes:
- Non-folding queries prevent partition pushdown.
- Data source limitations (e.g., certain data sources do not support partitioned queries).
- Solutions:
- Check query folding using View Native Query in Power Query.
- Adjust transformations to ensure query folding remains intact.
If query folding warnings were ignored:
- Possible Consequences:
- Partitions may appear but contain incorrect or duplicate row counts.
- Solutions:
- If a warning appears, test by running queries directly on the data source.
- Manually inspect partitions to ensure expected behavior.
- Use DAX Studio or SSMS to verify row distributions.
Conclusion
Verifying incremental refresh ensures efficient data management and performance optimization. Always check partition creation and row counts after setup. If issues arise, investigate query folding, IR settings, and data source compatibility. Implementing validation checks proactively can prevent data duplication and ensure the performance benefits of incremental refresh.